Mouse gliogenesis
This tutorial will walk you through the different steps to train a neural network to learn a differentaition potential from spatial transcirptomics through time, using STORIES. As a demo dataset, we will use a subset of dorsal midbrain data from the MOSTA dataset by Chen et al., containing radial glia cells, neuroblasts and glioblasts.
Imports
STORIES relies on AnnData for input/output, and on the JAX ecosystem for GPU computations.
[1]:
import os
import anndata as ad
import matplotlib.pyplot as plt
import numpy as np
import optax
import scanpy as sc
import stories
Check that JAX detects the GPU. If not, refer to the JAX installation page.
[2]:
import jax
jax.devices()
[2]:
[cuda(id=0)]
Load the data
You can download the processed demo dataset in the .h5ad format from this Figshare link. The original data comes from the MOSTA dataset.
[3]:
#!wget -O dorsal_midbrain_processed.h5ad https://figshare.com/ndownloader/files/47843353?private_link=07591a104a4463f11b85
The important fields for this tutorial are the following:
adata.obs["time"]: a number indicating the time point. Time points do not have to be evenly spaced. Importantly, STORIES assumes one slice per timepoint.adata.obs["growth"]: a score computed based on estimated proliferation and apoptosis rates, which estimated the number of descendants of a cell. STORIES can weight cells proportionally to such a score. This is optional, and by default all cells have the same weight.adata.obsm["X_pca_harmony"]: a batch-corrected PCA embedding of gene expression data. This is the input of the model.adata.obsm["X_isomap"]: a 2D embedding of the data. Here, we use Isomap, but you could used PHATE or UMAP instead.adata.obsm["spatial"]: 2D spatial coordinates of the cells.
[4]:
# Load the data
adata = ad.read_h5ad("dorsal_midbrain_processed.h5ad")
Preprocess the data
In order to make the gene expression and spatial terms more comparable, we suggest some basic rescaling of the data.
[5]:
# Select a given number of principal components then normalize the embedding.
adata.obsm["X_pca_harmony"] = adata.obsm["X_pca_harmony"][:, :20]
adata.obsm["X_pca_harmony"] /= adata.obsm["X_pca_harmony"].max()
[6]:
# Center and scale each batch in space.
# Importantly, we have only one slice per time point.
adata.obsm["spatial"] = adata.obsm["spatial"].astype(float)
for t in adata.obs["time"].unique():
idx = adata.obs["time"] == t
mu = np.mean(adata.obsm["spatial"][idx, :], axis=0)
adata.obsm["spatial"][idx, :] -= mu
std = np.std(adata.obsm["spatial"][idx, :], axis=0)
adata.obsm["spatial"][idx, :] /= std
[7]:
fig, axes = plt.subplots(
1, 3, figsize=(15, 5), sharey=True, sharex=True, constrained_layout=True
)
for i, t in enumerate(sorted(adata.obs["time"].unique())):
idx = adata.obs["time"] == t
sc.pl.embedding(
adata[idx], "spatial", color="annotation", s=20, ax=axes[i], show=False
)

Train the model
The most important parameter when defining the model is the relative weight of space comapred to gene expression. Here, we set it to 1e-3. Larger values will give more importance to space, and a value of 0 will ignore space.
[8]:
model = stories.SpaceTime(quadratic_weight=1e-3)
Now, we can start to train the model. model.fit() accepts additional parameters such as the number of iterations, and the batch size. We use AdamW with a cosine decay as an optimizer. The training will stop when the validation loss stops improving, and weights corresponding to the best validation loss are kept.
[9]:
scheduler = optax.cosine_decay_schedule(1e-2, 10_000)
model.fit(
adata=adata,
time_key="time",
omics_key="X_pca_harmony",
space_key="spatial",
weight_key="growth",
optimizer=optax.adamw(scheduler),
checkpoint_manager=f"{os.getcwd()}/ckpt_midbrain",
)
20%|█▉ | 1963/10000 [05:59<24:31, 5.46it/s, iteration=1964, train_loss=0.023269247, val_loss=0.030355781]
Met early stopping criteria, breaking...
Display the potential
STORIES learned a potential function. Let us apply it to all cells, populating the AnnData object with a new field adata.obs["potential"].
[10]:
stories.tools.compute_potential(adata, model, "X_pca_harmony")
[11]:
sc.pl.embedding(
adata,
basis="isomap",
color=["annotation", "potential"],
vmax="p98", # Colorbar up to the 98th percentile
vmin="p02", # Colorbar down to the 2nd percentile
)

Display the velocity
The opposite of the potential’s gradient points towards more differentiated states. Let us compute this velocity for all cells, populating the AnnData object with a new field adata.obsm["X_velo"].
[12]:
stories.tools.compute_velocity(adata, model, "X_pca_harmony")
STORIES provides a convenient wrapper function around CellRank to visualize this velocity. A branching from RGC to NeuroB and GlioB clearly emerges.
[13]:
palette = {"GlioB": "#008941ff", "NeuB": "#ff34ffff", "RGC": "#00bfffff"}
[14]:
stories.tools.plot_velocity(
adata,
"X_pca_harmony",
basis="isomap",
color="annotation",
palette=palette,
s=50,
)
100%|██████████| 4581/4581 [00:02<00:00, 2056.65cell/s]
100%|██████████| 4581/4581 [00:01<00:00, 3187.13cell/s]

Gene trends
Let us explore the gliogenesis trajectory in more detail. We can subset the AnnData to the cell types of interest.
[15]:
adata = adata[adata.obs["annotation"].isin(["RGC", "GlioB"])].copy()
Gene trends are usually computed on smoothed count data. Here, we used MAGIC on the harmonized PCA space to account for batch correction.
[16]:
# pip install magic-impute
import magic
magic_operator = magic.MAGIC()
magic_operator.fit(adata.obsm["X_pca_harmony"])
diff_op_t = np.linalg.matrix_power(magic_operator.diff_op.A, 3)
adata.X = diff_op_t @ np.log1p(adata.layers["counts"].A)
Running MAGIC on 3643 cells and 20 genes.
Calculating graph and diffusion operator...
Calculating KNN search...
Calculated KNN search in 0.38 seconds.
Calculating affinities...
Calculated affinities in 0.39 seconds.
Calculated graph and diffusion operator in 0.78 seconds.
For each gene, let us regress the smoothed gene expression from the potential. By default, this is done with a spline regression but you can specify your own model. This populates the AnnData object with a new layer, adata.layers["regression"], and gene-wise information: adata.var["regression_score"] (how good the fit is), and adata.var["regression_argmax"] (for which potential the highest regressed expression is achieved).
[17]:
stories.tools.regress_genes(adata)
10000it [01:24, 118.00it/s]
We can represent this information conveniently using the following function. Since cells are ranks with increasing potential, the differentiation process goes from right to left.
[18]:
sorted_genes_names = stories.tools.select_driver_genes(adata, n_stages=2, n_genes=15)
fig, axes = stories.tools.plot_gene_trends(
adata, sorted_genes_names, title="Gene trends along gliogenesis"
)

The plot above shows regressed gene expression. The function plot_single_gene_trend enables to plot the original gene expression along the potential.
[19]:
stories.tools.plot_single_gene_trend(adata, "Mki67", s=5, palette=palette, alpha=0.75)
stories.tools.plot_single_gene_trend(adata, "Aldh1l1", s=5, palette=palette, alpha=0.75)


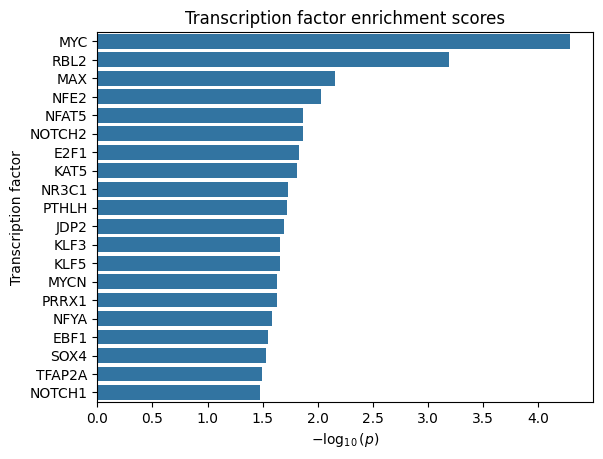
Transcription factors
Finally, STORIES provides a function to perform a Wilcoxon rank-sum test for TF enrichment among the best-scoring genes. It expects a TSV file from the TRRUST database, which has a file for mouse and a file for human TF-target interactions.
[20]:
#!wget https://www.grnpedia.org/trrust/data/trrust_rawdata.mouse.tsv
[21]:
stories.tools.tf_enrich(adata, trrust_path="trrust_rawdata.mouse.tsv")
100%|██████████| 599/599 [00:02<00:00, 242.83it/s]
100%|██████████| 599/599 [00:01<00:00, 345.17it/s]